
We have updated our Privacy Policy, click here for more information.
Thank you

In a similar vein to the decision to implement Calypso, the decision to implement Kubernetes is a large undertaking for any organization irrespective of its size. It’s a complex system that requires understanding of many factors, not least the restructuring of current development practices. In fact, when it comes to using Kubernetes, the best value comes from fully adopting a DevOps culture. Traditionally implementing DevOps processes for Calypso was an immensely time-consuming undertaking but recent improvements such as the built-in support for Containers and move to Spring Boot have made this much easier. Kubernetes isn’t just installing something on a virtual machine (VM), it’s a transformative and revolutionary way of viewing IT and enabling your teams. Automation is a direct path to becoming more productive and spending time on the things that matter.
Kubernetes can make every aspect of your Calypso installation accessible to automation, including role-based access controls, ports, databases, storage, networking, container builds, security scanning, and more. Kubernetes gives teams a well-documented and proven system that they can use to automate so that they can focus on outcomes.
Most of the organizations that have implemented Calypso will know that it can be a complicated system to put in place. There are many dependencies and pre-requisites to a successful implementation that will already have taken up many resources. Part of this journey will include quantifying those and streamlining them to become automation friendly.
In this white paper, you’ll find recommendations for every phase of the Kubernetes adoption journey and how that applies to Calypso. From Discovery and Development through Staging, Production, and ultimately Scale, we’ll offer a simple yet comprehensive approach to getting the most out of Kubernetes and how it can work cohesively with Calypso. We’ll walk you through some best practices for any Kubernetes deployment, plus recommendations for tools and how to get started using any Kubernetes implementation, whether it’s enterprise wide or on a single development machine.
In a nutshell, container orchestration tools, like Kubernetes, help organizations manage complex applications, scale automatically to meet demand and conserve resources.
Internal teams manage the containers that run applications. These containers are then instantiated within Kubernetes. If one container fails, another is created to take its place. Kubernetes handles this changeover automatically and efficiently by restarting, replacing, and killing failed containers that don’t respond to a health check. The goal here is to minimize the downtime experienced by an application. Applications should be built with resiliency do withstand another part of the application experiencing a changeover. To express this in Calypso terminology any part of the Calypso ecosystem like the Engineserver or Riskserver should be able to withstand and recover from a Dataserver failover event.
Servers can be grouped into logical clusters, allocated according to a variety of parameters and it also monitors these clusters and decides where to launch containers based on the resources currently being consumed — which means it’s useful for scaling, deployment, and general application management.
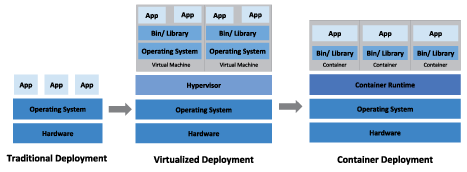
Containers, such as those implemented by Docker, have become popular because they provide extra benefits, such as:
Calypso now provides out of the box support for generating containers and running containers either from Docker or Kubernetes.
One significant point to note is that as of the current time Docker and Kubernetes support is only provided for clients that run on Linux.
After the installation of the base package of Calypso and running the image generation script, the following types of image are made available:
Once the images have been generated you are now able to create a working Calypso environment running on Docker. Typically, you would do this through the creation of a single Docker Compose file.
Given that most clients looking to run Calypso on Kubernetes will have some form of specialization in their installation, it is recommended to use the “calypso-application” image as a base to generate a custom image which contains any required specializations. Taking this a step further, this process can be automated to create a pipeline that will auto generate Docker images every time a new Calypso Maintenance Release (MR) is released.
For Kubernetes to manage an application it needs to be able to determine the current health of said application.
All of the servers provided by Calypso now have a REST based Health Check API available. This exposes several sets of data any combination of which can be used by Kubernetes to determine how application failover should be handled.
During the Discovery phase of a Kubernetes implementation, teams will explore their options for using Kubernetes and begin to plan their infrastructure on a block level or by grouping together one or more infrastructure resources. The Discovery phase of the Kubernetes adoption journey is unique to you and your business, and you’ll decide how your application will best map to a Kubernetes infrastructure. With effective planning, you can move from Discovery to Production and Scale in as little as a few weeks.
As your team begins to plan moving infrastructure to Kubernetes, find out what tech stack you need to be most successful, both now and in the future. Understanding the reason you want to use Kubernetes is key to deciding what types of components you’ll need to evaluate. Whether you’re looking to streamline the development lifecycle by having a hassle-free Kubernetes cluster, looking to accelerate testing by being able to provision installations on demand or an enterprise that needs dynamic scaling capabilities we can guide you so that you can effectively achieve your goals.
As you architect your infrastructure, consider the following:
Consider if your team will use a managed or self-hosted version of Kubernetes. While there are times when it makes sense to self-host Kubernetes, maintaining self-hosted clusters is time and resource intensive and requires a level of expertise that only enterprise level organizations will have. Managed Kubernetes like OpenShift, Amazon EKS or Azure AKS bears the burden of managing the control plane, ensuring high availability with the latest security patches and release updates, providing autoscaling capabilities, and more. Businesses leveraging Managed Kubernetes often have a faster release cycle.
Do you want all Calypso and related services to run on Kubernetes or is the intention that they be distributed across Kubernetes, VMs, physical on premise servers and other compute platforms? For example, you may want to keep the Calypso server components on Kubernetes while running the Scheduler on an on-premise server. As mentioned later having a heterogenous environment would have implications on the management and complexity of your Kubernetes deployments.
Open source software like Kubernetes allows startups to avoid vendor lock-in by facilitating migrating projects to other clouds or spreading workloads across multiple clouds, while Infrastructure as Code (IaC) tools like Terraform easily provision environments across multiple providers. With Kubernetes, teams can pick up their whole infrastructure and run it the same way in different environments, easily moving networking, applications, databases, and even things like secrets. Using Kubernetes, organizations can seamlessly mix and match services from different providers to best fit their solution or in certain cases host the cluster on premise.
Kubernetes provides a consistently proven system across clouds that can lessen the technical debt of multi-cloud environments. If you include Infrastructure as Code (IaC), tools like Terraform, Ansible, Pulumi, and many more have further simplified provisioning across clouds, all of which can be fully automated through DevOps workflows.
An oversized cluster is inefficient with its resources and costs more, but an undersized cluster running at full CPU or memory suffers performance issues and can crash under stress. Look at your node size and count to determine the overall CPU, RAM, and storage of your cluster. Larger nodes are easier to manage, in many cases are more cost-efficient, and can run more demanding applications; however, they require more pod management and cause a larger impact if they fail.
While many enterprises have immediate access employees with a deep knowledge of databases, smaller organizations usually have fewer resources available and may not have on site DBAs. This makes tasks like replication, migrations, and backups more difficult and time-consuming. Managed Databases handle common database administration tasks such as setup, backups, and updates so you can focus more on your app and less on the database.
Additionally, you may want to empower your development team by giving them control of Databases within a dedicated cluster.
There is also the possibility of adding efficiency to your release lifecycle by automating parts of your database management in a new pipeline.
In many organizations there may often be contention for Calypso environments for testing – it could be for BAU, upgrades or Proof of Concept projects. It would be possible to have a user drive process to trigger spinning up a fully working Calypso environment from scratch with the latest code and database, have that undergo automated testing and be ready for use in a few minutes. The user can then carry out the required manual testing not covered by the automated tests.
Once the environment is no longer required it can be safely destroyed and any manual testing can be converted into automated tests so that in the next testing cycle the most recently run tests are not repeated.
The Development phase of a Kubernetes implementation focuses on developer workflow and efficiency. Significant operational complexities come into play potentially from the moment the developer starts writing code to the time the developer commits their code all the way up until it’s deployed in a Kubernetes cluster. Understanding an optimal developer workflow can help teams build, test, and deploy faster, ultimately enabling the business to increase productivity and innovate faster. In order to move into the Development phase, your team needs to have the basic tooling for Kubernetes in place, and the application should be running in a development environment.
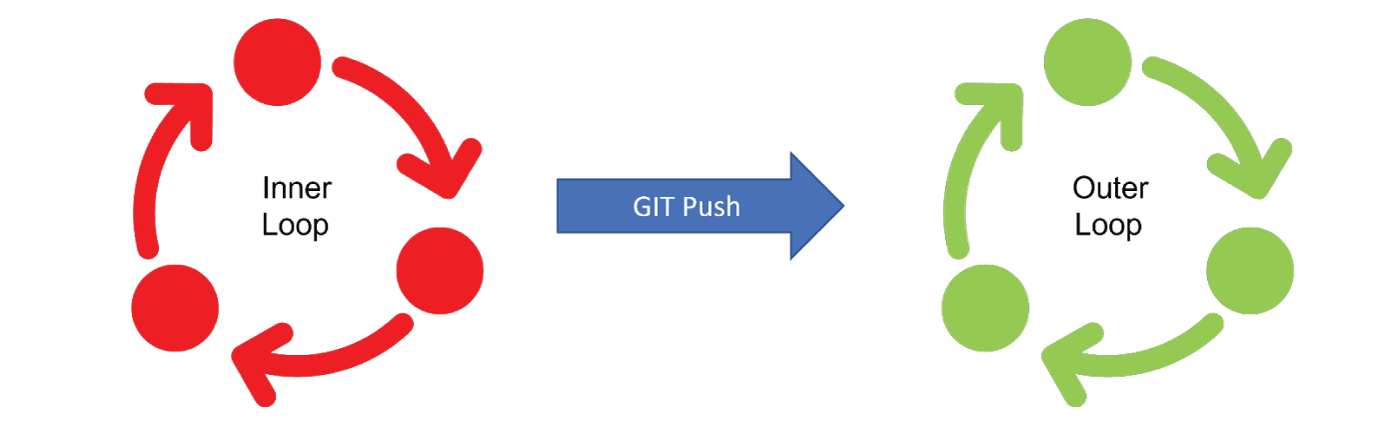
A typical developer workflow consists of several cycles of an inner development loop and an outer development loop.
An Inner Loop includes coding, building, running, and testing the application and it takes place on the developer’s machine before committing the code to the source code repository. This phase can happen several times and depending on the complexity of the work can be extremely variable in scope and time taken to complete.
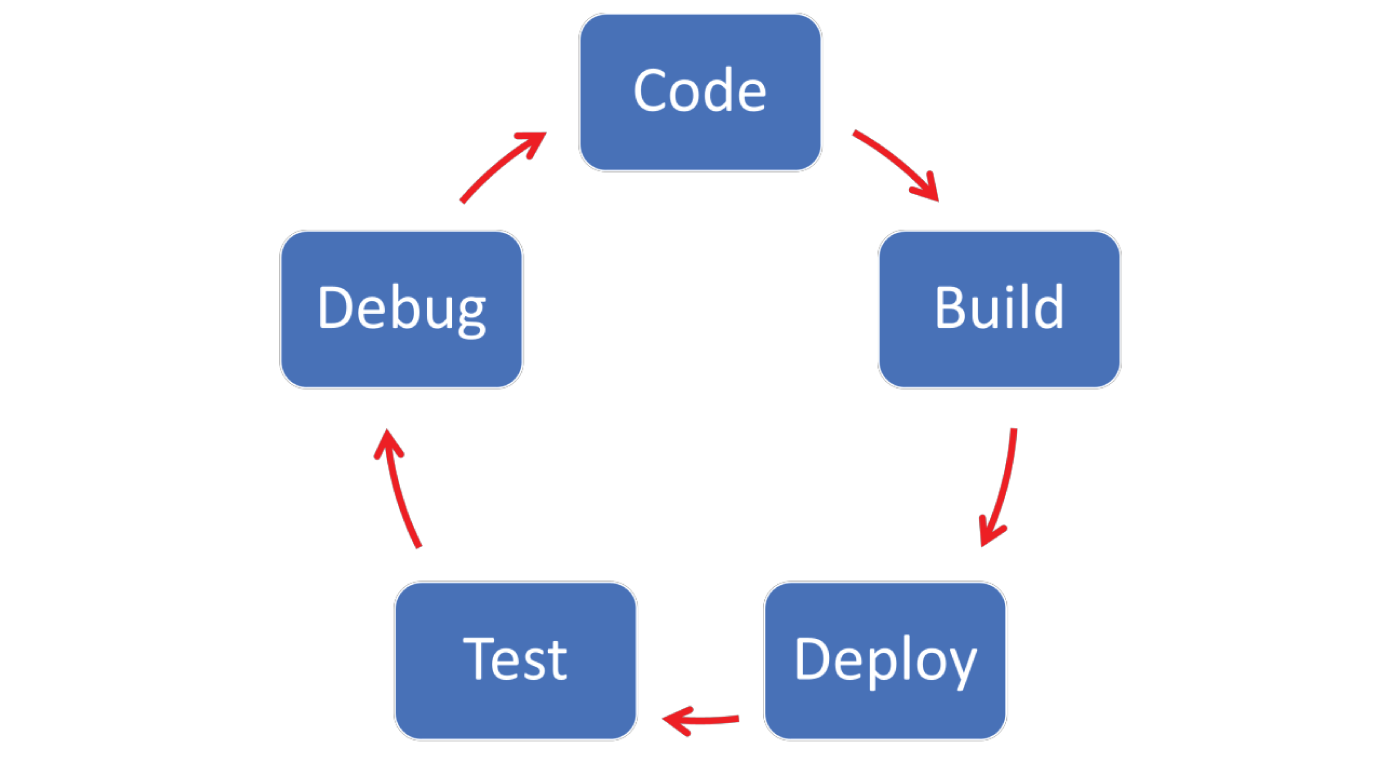
This is an iterative process and it’s the phase before the developer shares the changes done locally with others.
An Outer Loop is made up of several cycles, including code merge, code review, build artifact, test execution, and deployment in a shared dev/staging/production environment. Apart from the Code Review everything in this loop should be automated as much as possible. Additionally, apart from the Code Review all the stages in this loop should be a fixed length of time.
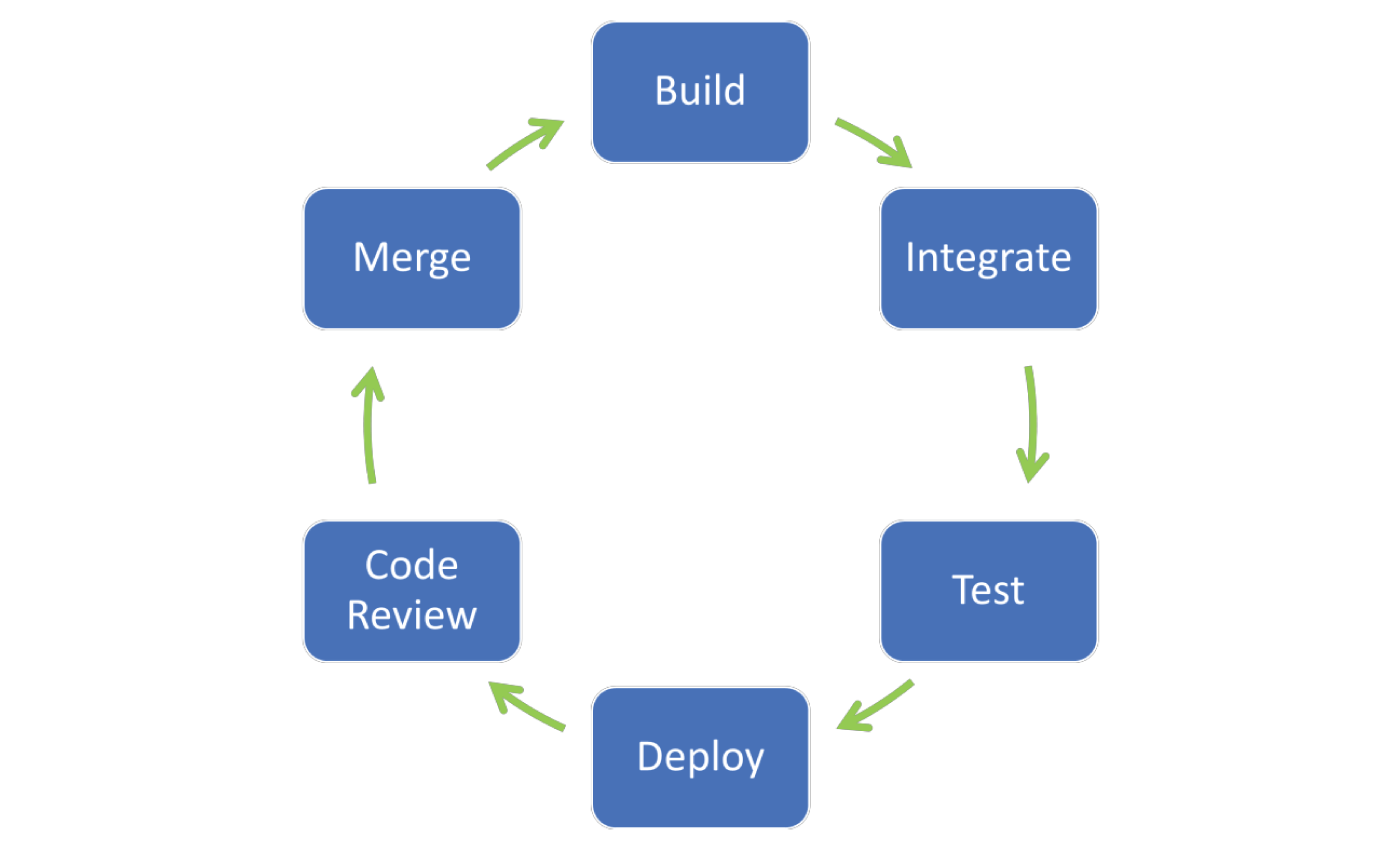
The developer’s “commit and push” to the source code repository from the inner development loop triggers the outer development loop.
As a developer, if you code x minutes per day in a traditional local iterative development loop of y minutes, you can expect to make about x/y iterations of your code per day. When you bring “containerization” in, it takes additional z minutes to
Correspondingly this will reduce the number of iterations down to x/(y+z).
Building and developing containers can slow down this inner development loop that impacts the total cycle time.
The default inner loop in Kubernetes can potentially take a long time and could impact developer productivity. Due to this, the CI/CD pipeline should not be an inner loop for development. The primary goal of the development phase is to create a development setup that makes the inner loop faster, in a similar manner to if you are building an application and running it on your workstation.
In order to achieve the inner loop of application development, teams need to focus on three areas. First, creating the development cluster, including local and remote setup.
In this case local would mean an on premise machine. It could be a laptop or workstation used by a single developer or it could be a server located within the organization used by a team.
Remote would refer to a machine either in the cloud or running within a managed Kubernetes installation which in this case would mean something like RedHat OpenShift, Amazon EKS or Azure AKS.
Next, installing basic tools for working efficiently with the cluster, and finally, setting up development tooling and workflow for rapid application development.
The options available for Development Clusters are Local and Remote. Your specific use cases and available resources are the main determining factors to consider when establishing a development cluster.
| Local Cluster | Remote Cluster | |
| When to use |
|
|
| Advantages |
|
|
| Disadvantages |
|
|
There are several options available to create local Kubernetes clusters for Calypso development, such as MicroK8s, K3d, Minikube and Rancher Desktop. Docker Desktop is also an option but now has an additional license cost from commercial environments.
While running a local Kubernetes cluster cannot be rivalled for speed of deployment and ease of use it is still limited by CPU, Memory and disk constraints of the local environment.
The main benefit of a remote cluster is that the setup and maintenance of the control plane is removed. Additionally, the management overhead of configuring, maintaining and scaling the cluster is removed. This will allow your team to focus on the task of building and optimizing your Calypso environment.
Every distribution of Kubernetes will have prepackaged tools available upon installation. These tools are suitable for basic operations but there are several third party tools available which will help with daily operations.
There are several tools that will help with automatic builds and deployments onto a Kubernetes cluster.
The Calypso software development lifecycle is a topic worthy of a separate discussion as there are already so many permutations of tools and applications available then adding Kubernetes to the mix complicates things even further.
Having said that we’ll touch upon the additional considerations and options available when running development instances of Calypso on Kubernetes, more specifically we will be examining the issues of maintaining Calypso releases and debugging Calypso when running within Kubernetes.
When Calypso releases a new version of their software there will need to be a process in place to take that release and make it available for your Devops pipeline. Since the intention is to develop custom code which will ultimately be deployed into a Calypso instance running on Kubernetes there will need to be a process which generates the Docker images and there will need to be a process that uploads the required development artifacts into a Maven repo.
Apart from the initial download from Adenzas web page this entire process can (and should) be automated.
The basic outline of the process should be as follows
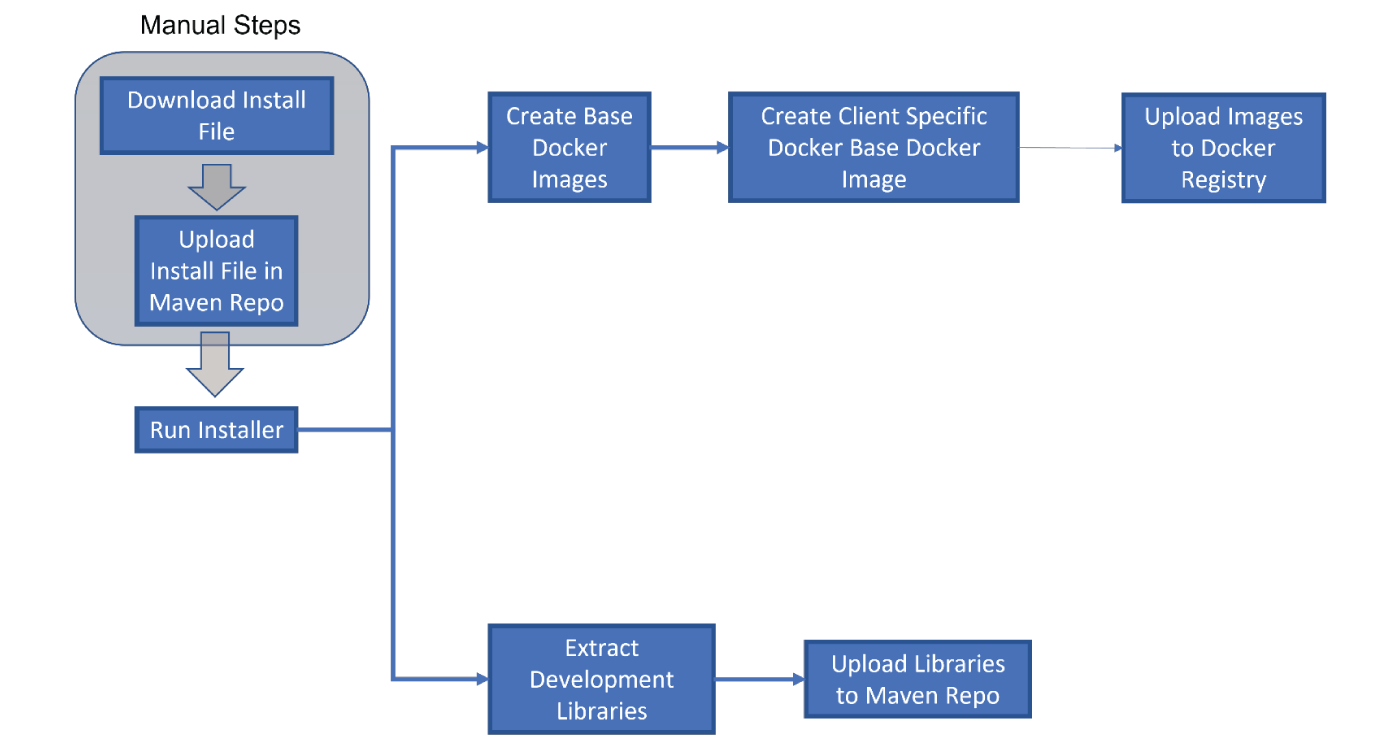
This flow could be further modified in many ways to accommodate business needs. One example could be to automatically build the custom code, automatically deploy the client custom images into a cluster and then run a set of automated tests. This would be a very quick way of checking that the new release of Calypso does not break any existing functionality.
Most Calypso developers should be familiar with debugging components of Calypso locally but the challenge here is that many of their existing local debugging tools and practices can’t be used when everything is running in a container.
Easy and efficient debugging is essential to being a productive developer. However, when you are working with a Calypso installation running in a Kubernetes cluster, the approach you take to debugging must change.
Using the tools that come bundled with Kubernetes there would normally be two approaches to debugging code that runs in a container:
The favoured solution to this problem would be to use an application called Telepresence.
Telepresence can be used to tackle the issues arising from both of the solutions presented above. It does this by setting up a two-way proxy between your local machine and the remote Kubernetes cluster, which lets you debug your services that are running locally as if they were running in the cluster.
For instance, you could start an instance of an Engineserver on your local machine, then inject it into the cluster using Telepresence.
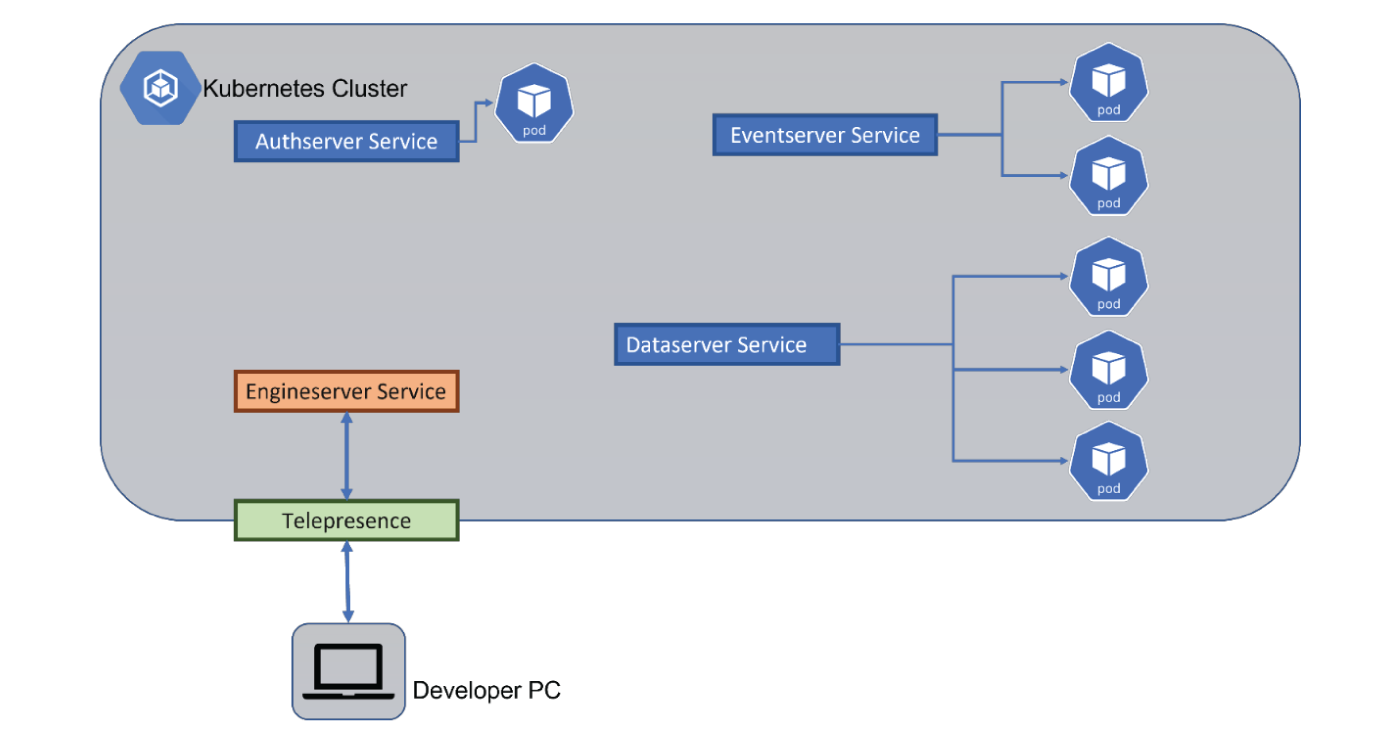
This now gives you the ability to debug code locally but have it “deployed” in the cluster.
At this stage you should have Calypso up and running in a cluster based development environment. This stage is going to focus on the path to testing your Calypso environment and ultimately ending with the push into production. CI/CD (Continuous Integration and Deployment) readiness revolves around the DevOps and automation practices that streamline your deployment flow. These practices are not limited to a specific application or toolset, but more of a change of mindset on how to approach the Software Development Lifecycle.
In general, the requirements for having a fully automated release process should include (but are not limited to) the following points.
Even if a full CI/CD pipeline is not required the above points will help to increase the quality of your Calypso environment.
This is a high-level representation of a code delivery pipeline. Bear in mind that this is not limited to Calypso and can be applied to any software development process.
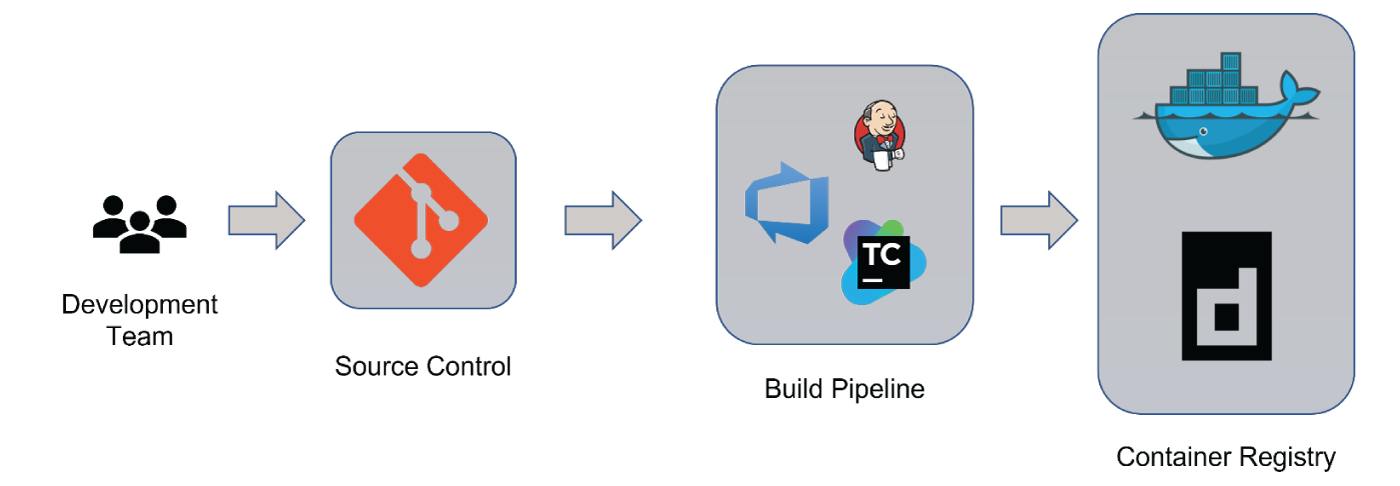
The development team commits code into source control (usually git but can include other SCMs). This will kickstart the build pipeline. Pipeline lines can be configured to run when new code is committed or on a fixed cycle, such as nightly.
There are several options for managing how you store Calypso code and configuration in source control.
Where no formal methodology is used then GitHub flow is simple to start with and is well used within many organizations.
As you continue to update your Calypso code and configuration, you need to build new images for testing. This is done using a build pipeline. There are many mature tools available with which you can implement a pipeline. Depending on your needs, the trigger for building a new image can be ad-hoc, based on conditions set within source control or can be a fixed cycle, such as nightly or weekly.
In order to find issues as soon as possible the build should be run as frequently as possible but bear in mind that disk space consumed by the container registry increases with each build. Depending on where your container registry is located you may have disk space or cost issues, so it would be recommended to have a clearly defined retention policy for your container images to minimize disruption for your build process.
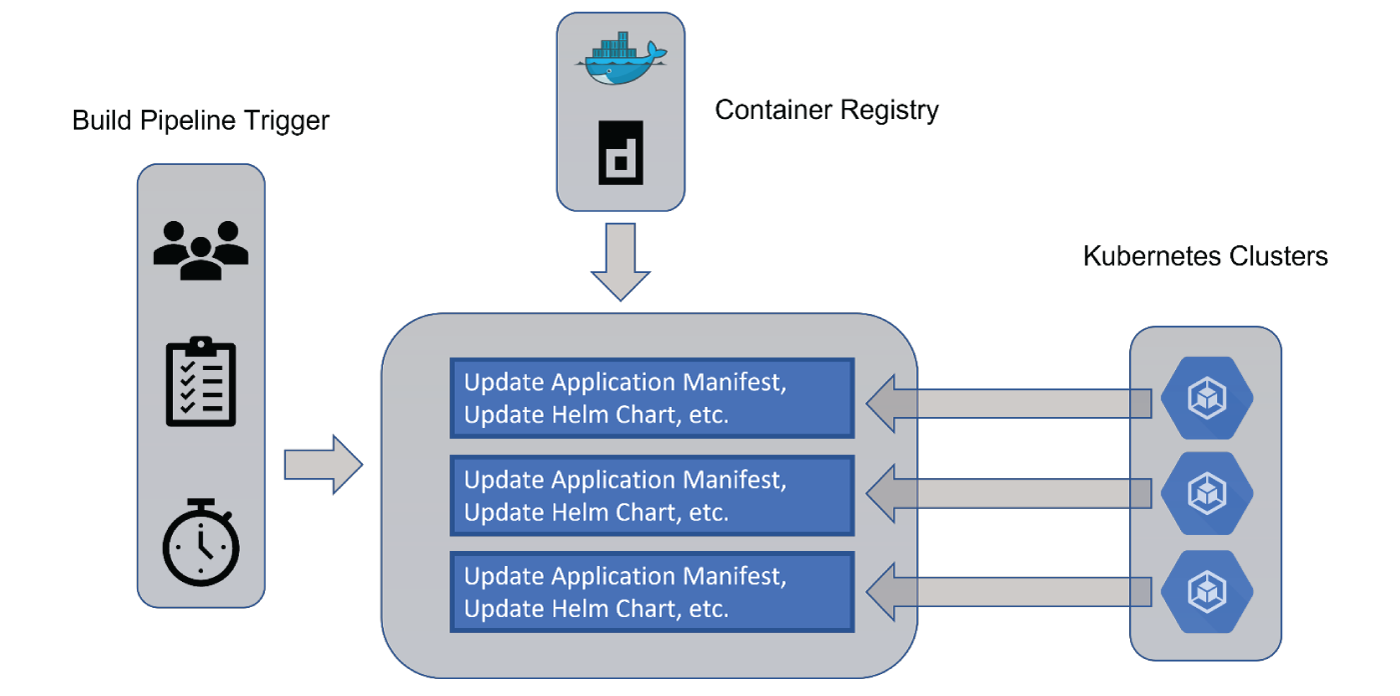
The CI pipeline has pushed the new application image, ideally with a new tag, to the image registry. Tagging images is always recommended in order to allow for easy rollbacks and regression testing. Now, the application image needs to be deployed onto the cluster. A Kubernetes cluster needs application metadata in the form of a YAML file, a Helm chart or others. You must store and version the application metadata in the git repository. Typically, you would store your Calypso application code and metadata within separate source code repositories. It would also be tempting to store different levels of configuration metadata in separate repositories e.g. one repo for dev config, one for UAT config and one for prod config. This is discouraged as the aim here is to have the same configuration used between all levels of environment, so you should aim to have a single source code repository for all configurations.
The level of automation in a project should be driven by a combination of current business needs and available skillset within your team. Identifying and implementing automation should be a recurring objective to help with successful releases of Calypso.
This implementation journey could be broken down into tranches, each of which can be enabled sequentially over a longer period of time.
For example, you could adopt the following pattern of implementation. Each phase could last weeks or months depending on the appetite for carrying out full automation.
This is a very high-level overview of what could be achieved but in order to make a determination of the final state that you wish to aim for the following topics should be considered.
For any corporate environment at a minimum there should be at least one UAT/Staging cluster in addition to the production cluster. Whether on-premise or in the cloud there will be a cost implication to running these that cannot be avoided.
For your developers to be able to work effectively there should be at least one development cluster. Depending on the size of your team you may be able to allocate a cluster per developer although the possibility of costs escalating exists.
Depending on other factors relevant to your Calypso environment – e.g. Number of users, external connectivity – Bloomberg, Acadia etc, internal upstream and downstream systems – you may need to use additional resources in the cluster like managed databases, load balancers and object storage. There would be a one-time effort in mapping and creating manifests for these resources.
When taking into account the number of Calypso environments required, there may be the possibility that you will need to have many production clusters, meaning you’re looking at many variations of the application manifest with different levels of customizations. The structure of how this is maintained is very important. This will avoid manifest sprawl and improve maintainability.
In order to have an automated pipeline where you have a high level of confidence in the operation of your Calypso environment you would need to ensure that you have as complete a level of test code coverage as possible.
In order to reduce the time spent carrying out manual testing then time and effort will need to be spent on automated testing.
For Calypso this can be broken down into unit testing on the individual class level, integration testing using something like Cucumber and functional testing using CATT.
Increasing test coverage should be a long-term goal for any project.
When it comes to managing software deployed onto clustered environments the “Golden Source” for the configuration should be maintained in source control. Over time the possibility of the configuration state of the cluster changing, compared to that in source control, increases. This could be down to manual changes, external changes or the configuration changing in the source without a respective deployment.
Adopting a dynamic operations model would mean that the state of the cluster would automatically synchronize with the configuration stored in source control. There are tools such as ArgoCD or Flux that could become part of the CI pipeline which would help if this was required.
Given that Calypso has a tight coupling to the database against which it runs the operation of rolling back to a previous version of Calypso is not such a straightforward process. In order to have a seamless rollback facility the database would need to be part of the configuration metadata.
The big problem with this approach is keeping a record of any domain level updates to the database, for example trades entered post synchronization and pre rollback would potentially be lost. This would not be such a problem in a development environment or even a UAT environment but would most definitely be an issue in production.
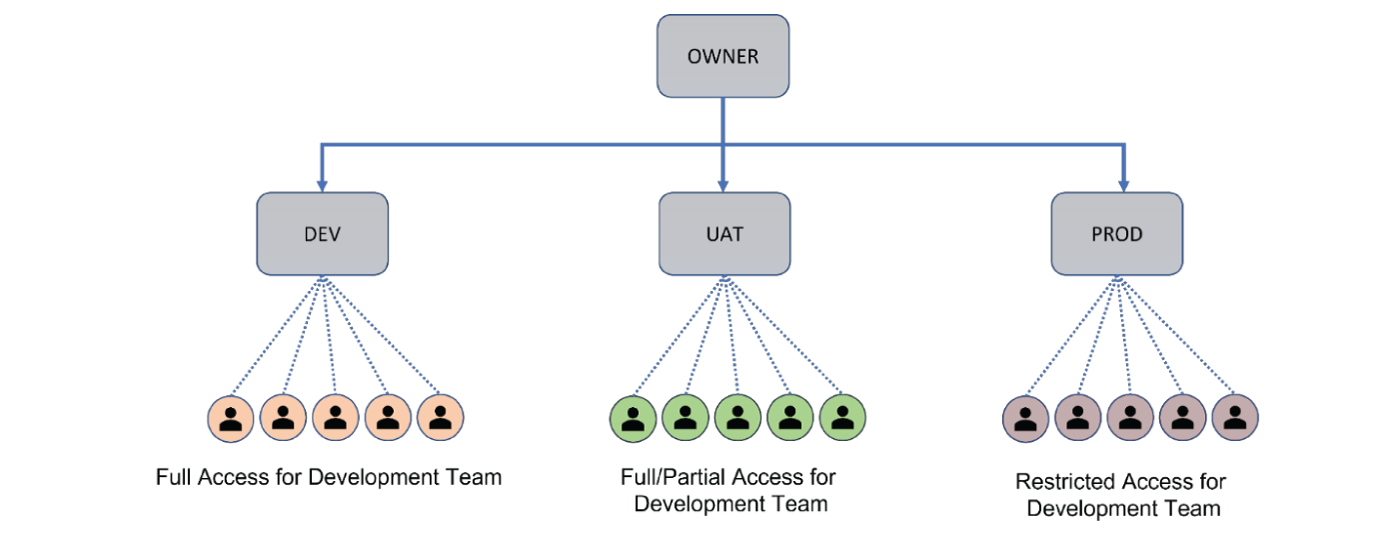
Some businesses may require different permissions structures. For example, it may be necessary to segregate access rights for different employees for infrastructure, applications, etc. based on their role. To address this, teams must start with the business need and then build the permissions structures, with the goal of avoiding duplication and ensuring that they can quickly carry out their tasks as required.
This is especially important where you have different teams assigned to different levels of applications i.e. You may have one team looking after development environments and one team looking after production environments. You should ensure that both teams are working from a common set of configuration files without duplication.
Security and maintaining the integrity of any application in an enterprise environment is of paramount importance.
Examples of secrets are things like passwords, ssh keys and third-party SaaS credentials. Both Calypso and Kubernetes will need to utilize secrets when running in an automated pipeline.
As a general rule, secrets shouldn’t be exposed outside of a cluster and since we are aiming to make the build process free from any human interaction, we will need a way to securely manage any secrets required by both Kubernetes and Calypso.
There are many tools available to encrypt the secrets outside the cluster the most notable types being
The recommendation here is to choose the external secrets operator because it has better security and less management overhead.
There are many permutations for configuration when it comes to CI/CD and almost every organization will have a different combination of tools available. The approach adopted will depend on the needs of your business, the access and authorization to resources across your company and the expertise of your team.
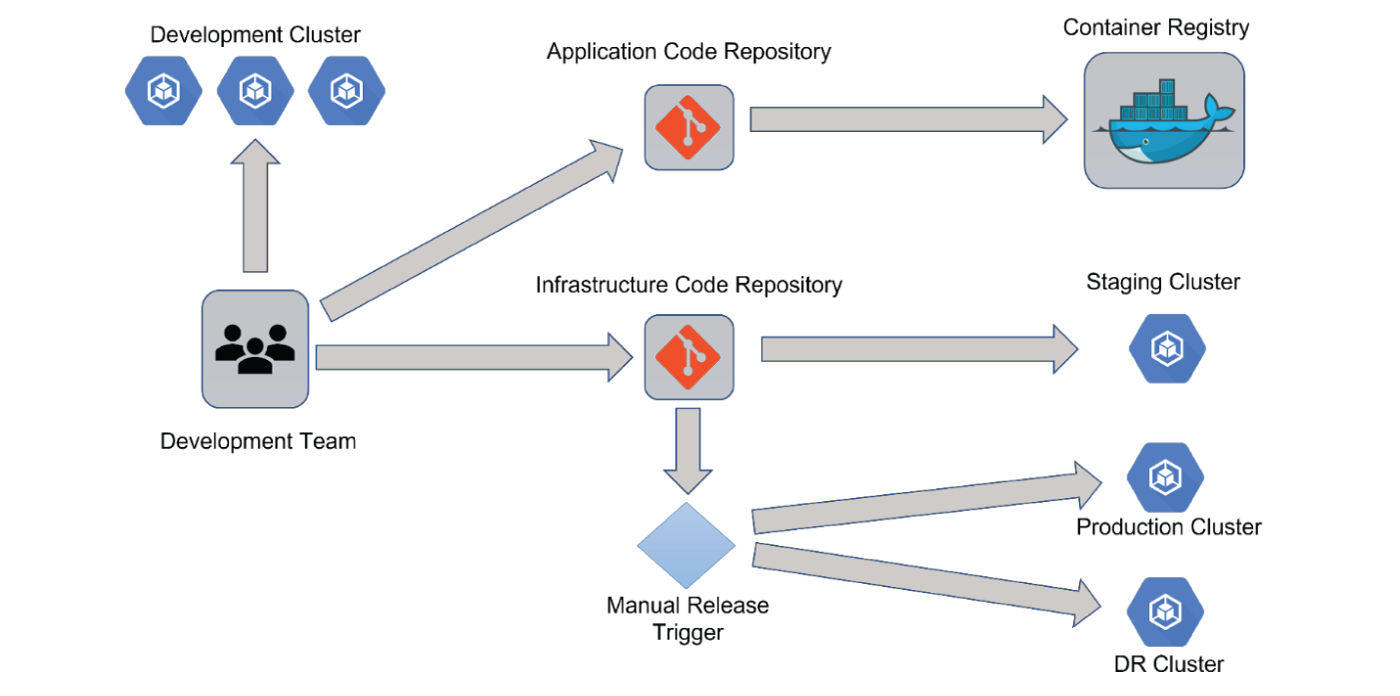
Preparing a Kubernetes cluster to be ready for production entails more than hosting a Calypso installation. Clusters should be built in anticipation of future needs but not necessarily built to meet those needs immediately. The needs consist of, but are not limited to things such as scalability, optimization, security, and disaster recovery. The following section focuses on features available (most) versions of Kubernetes.
Different Calypso applications have different CPU and memory requirements. Due to the way that Calypso is designed to be deployed into Kubernetes you will need to have at least a single machine per application and depending on the type of application the specifications of that machine will have to align to the requirements of the application.
Specifications to consider are:
Overall, the process is no different to selecting a physical machine to run Calypso.
If electing to use a managed Kubernetes instance, check if they have high availability. The Control Plane (master node) is the controller of the Kubernetes cluster. The components, including the API Server, Controller Manager, Scheduler, and more, exist within the control plane control and manage the worker nodes by efficiently scheduling resources and distributing workloads.
The production environment of Kubernetes should be built with scalability in mind so that teams don’t need to worry about Calypso application load and cluster performance with increased demand.
Generally, there should be three types of scaling available
When starting to use Kubernetes it would be recommended to use Cluster and Horizontal autoscaling. Once the clusters performance requirements become clear you could look to introduce the Vertical autoscaler.
Exposing and managing external access to software running within a cluster can be hard to manage
Ingress traffic is network traffic that originates from outside of the network’s routers and proceeds toward a destination inside of the network.
Kubernetes ingress is a collection of routing rules that govern how external users and systems access services running in a Kubernetes cluster.
Given that even the simplest Calypso installation will require connectivity to a variety of external systems the topic of Ingress is something that should be given special consideration.
There are three types of Kubernetes Ingress available
For Calypso services it would be recommended to run an Ingress Controller for the flexibility it provides.
A Kubernetes Ingress controller lets you route the traffic from outside the Kubernetes cluster to one or more services inside the cluster acting as a single point of entry for all the incoming traffic. This makes it the best option for the production environments. It can also handle much more than just load balancing and can scale up easily.
An example configuration for Calypso could look like the following
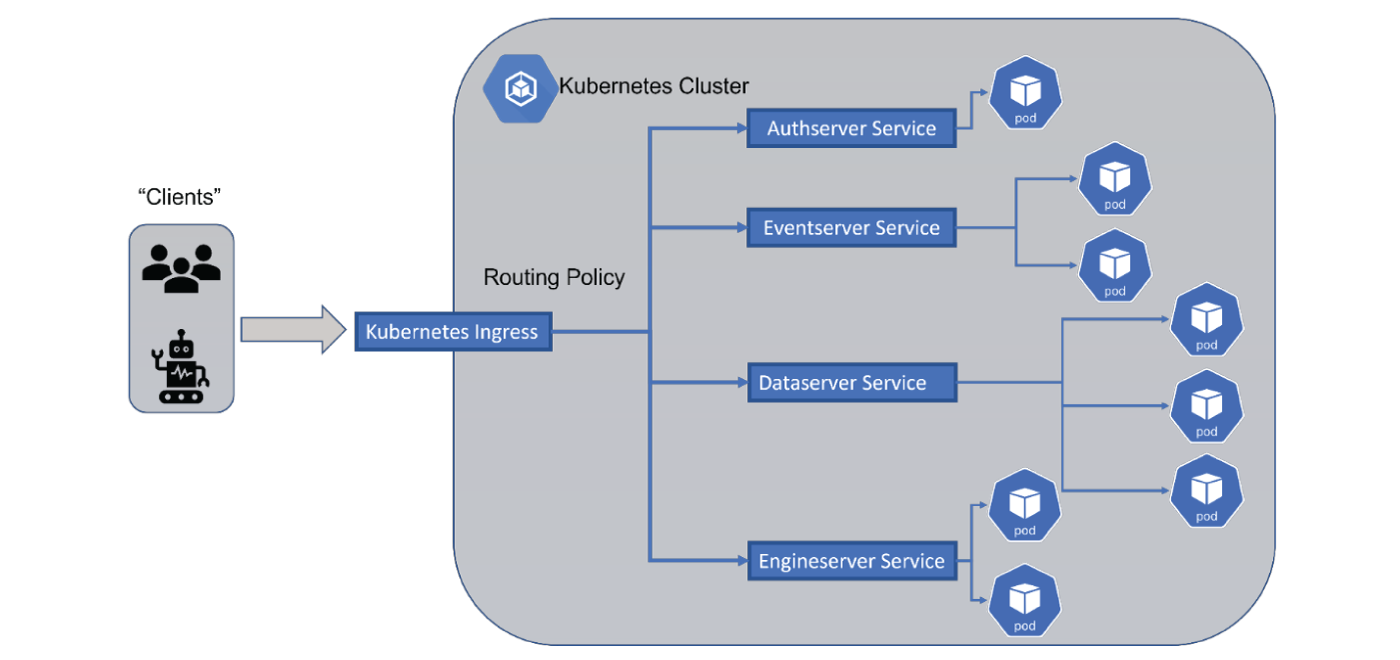
One thing to note is that there are many ingress implementations available for Kubernetes and depending on the needs of the business you may need to evaluate which one is most suitable for your organization.
Another thing to note is that now each of your Calypso instances is going to be identical internally within its respective cluster. It may have different run time parameters, such as environment name, but things like IP Address and machine names should be the same irrespective of whether the instance is for development or for production. This simplifies many configuration headaches within Calypso but also introduces new challenges as the identity of that instance is essentially defined via its Ingress configuration.
When running a production Kubernetes cluster, it’s important to have complete visibility into the health of the Kubernetes cluster and application workloads.
Observability helps teams understand what’s happening across environments and technologies so they can detect and resolve issues and keep systems efficient and reliable.
Calypso components now come an built in health check function, as a collection of REST APIs, which allows the Kubernetes control plane to effectively monitor the health of each part of the environment.
Without effective observability, any downtime in the cluster may result in increased time to recovery, resulting in an impact of business function and leading to user dissatisfaction.
The Calypso health check functions expose many metrics which can be used to fine tune the failover capability.
Observability is made up of the following main areas:
There are three aspects of monitoring you need to be aware of when running applications in Kubernetes:
Setting up a robust Kubernetes monitoring and alerting solution gives teams the ability to diagnose the issues that occurred, when they occurred and the location they occurred, optimize hardware utilization based on metrics alerting, optimize costs by removing underutilized resources, detect malicious ingress and egress traffic, and predict imminent problems.
There are several application performance monitoring tools available such as Grafana, Splunk and Datadog.
Most monitoring tools will have some form of alerting built-in but there are specialist alerting systems available if your business needs require it.
In order to run a stable Calypso environment creating a continuing record of cluster and application events through logging is essential to debug, trace back and troubleshoot any pod/container performance issue, audit for compliance needs, and identify event patterns for performance/scale forecasting. As your Kubernetes environment grows the sheer volume of data generated by the components and the applications contained within is tremendous, warranting a strong need for centralized logging that brings significant value to the users of Calypso and to your business.
There are four main areas when it comes to logging in Kubernetes
You should be able to implement a single toolset or stack of tools in order to facilitate all the logging requirements. A popular Open Source stack is ELK – Elasticsearch, Logstash and Kibana – although there are many options available.
At a minimum the chosen solution should be able to carry out this basic set of functionality:
When running a cluster, you will observe several Kubernetes specific events such as node/pod resource reallocations, rescheduling, and state transitions. These events are different from the logs generated by the Kubernetes components of the control plane and these events are not regular objects like logs. They are transient, typically persist for less than one hour and there is no built-in mechanism in Kubernetes to store events for a long period of time.
It would be prudent to set up event logging to be stored in your logging server because diagnosing any issues related to Kubernetes events will be made much easier.
As your Calypso environment in production begins to bed in you may need to scale the existing cluster in order to meet new requirements. This could be in the form of support for new Product Types, new Upstream or Downstream systems or regulatory requirements.
Increased focus must be placed on optimization of resource consumption and utilization.
Optimization should start by developing a thorough understanding of the performance characteristics of Calypso when running in a cluster. There will be an outline of the special consideration required when running Java based applications in a Kubernetes cluster.
The main tasks here are benchmarking memory, CPU, and Network I/O. Then shift focus onto measurements on the four “golden” signals:
As described in the section on Production, build out robust observability tools and set up actionable alerts. Alerts should be accompanied by runbooks that provide instructions to fix problems that require manual intervention.
Over time, automate the runbooks as much as possible to facilitate greater scaling. Once the automation is in place run simulations where your Calypso instance is stressed – There are various tools that will allow you to exercise different aspects of Calypso and place it under increased load.
You should also be able to use these automated runbooks for your applications and infrastructure by holding disaster recovery simulations periodically.
When running a Kubernetes cluster in a managed environment there will be some level of limits placed on the resources. This is primarily to ensure that the cluster remains viable and the Calypso instance within does not exhaust the available resources.
Optimizing Calypso within Kubernetes for scaling requires considering failure modes, the account, resilience, network, and CPU load, storage needs, dynamic runtime conditions, and deployment best practices.
Once an understanding of how Calypso operates within these limits you will have a better understanding of how to configure auto-scaling for your cluster so that your resources can grow appropriately on demand.
Execute realistic load tests to exercise the network paths to understand how your application will need to horizontally scale to handle expected and peak load.
As Calypso access requirements grow consider putting in place Roles Based access mechanism that will allow access to the Calypso applications within the cluster and then use the LDAP account sync within Calypso to keep the internal accounts within Calypso in sync.
For access to the Production cluster consider putting in place a certificate based access mechanism that will by default give time limited read only access to the cluster.
In order to operate effectively Calypso will require access to a filesystem. Given the nature of Kubernetes, the applications running within are effectively isolated from each other, so special consideration must be given to how files are read and written.
The simplest solution is to use Kubernetes Persistent Volume (PV). This is suitable if you want persistent storage that is independent of the life cycle of the pod. PV is an abstracted storage object that allows pods to access persistent storage on a storage device, defined via a Kubernetes StorageClass. The main downside of this is that access is limited to a single pod at a time.
Alternatively, you may want something like OpenEBS Dynamic PV NFS provisioner, which can be used to dynamically provision NFS Volumes using the block storage available on the Kubernetes nodes. The NFS provisioner runs an NFS server pod for each shared storage volume. Although more complicated to set up this will allow for shared file access between multiple pods at the same time. The primary downside of this is that the NFS server pod is now a single point of failure.
Kubernetes brings many benefits, such as improved resource utilization, shortened software development cycles, observability and consistent management of resources across your organization. Primarily, its self-healing and auto-scaling capabilities can ensure high reliability, guaranteed uptimes, improves performance and it often improves the user experience by improving product quality and stability.
Calypso has had many improvements made to its infrastructure that will allow it to take full advantage of all the benefits that Kubernetes can offer.
However, there is a cost in adopting and implementing these benefits.
The initial challenge is to determine where to begin and how, and then to be able to handle the technical complexities and cost investments along the adoption process.
Organizations wanting to use Calypso within the Kubernetes ecosystem will require a disciplined change program but invariably the biggest change required is a shift in mindset, from two main perspectives – the organization and the development team.